Chat with your PDFs using LangChain🗣️
Highly driven Backend Engineer with 1.5+ years of experience in Java, Spring Boot, and microservices, experienced in delivering scalable, production-grade systems in fast-paced startup environments.
AI tools and apps are all over the place since ChatGPT came into existence, all thanks to OpenAI and rightly so, we all have been using all these tools to make our daily work easier and faster to complete.

But, ever thought of making some of these tools by yourself?
Now I know, you must have wanted to make some of these, but let's be honest, most of us think about AI & ML stuff as something which requires maths and a computer with good specifications, things which most of us don't have.
But, gone are the days when we needed these things to use & create something with AI. With frameworks such as LangChain, it has become extremely easy for anybody to create something with AI. And with OpenAI API available to developers like us, we don't need a computer with great specifications to train AI models anymore.
Now enough talking, let's get to the topic. In this blog, we are going to see some simple steps through which anybody (trust me, even a noob like me) can create a Chatbot which can read your PDF files and give you a response based on the content of the PDF file. We will make use of Streamlit to create a web frontend (as we are using Python), OpenAI API to use OpenAI Language Models & LangChain framework to work with them.
But, but, what is LangChain🦜🔗?
Before knowing about LangChain, we must understand what is an LLM. A Large Language Model is a type of Artificial Intelligence that uses advanced deep learning techniques and trains on a large amount of data to understand & generate text in a human-like fashion.
Talking about LangChain, it's an open-source framework that can be used to work with various large language models (LLMs) along with our own induced data.
But why do we need to induce our data? Well, LLMs are generally trained on a large amount of data and they can tell about all the basic things about every topic available, but they still might not be able to tell about the specific nitty-gritty of a particular topic. In such scenarios, it is very useful if you can induce the data of a particular book, your University Professor's notes or any other custom data to the LLMs & get responses to your queries based on them.
OpenAI has a lot of LLM models which we developers can use to create our custom AI tools by accessing their API. To know more about the type of models available, check this link "Models - OpenAI API".
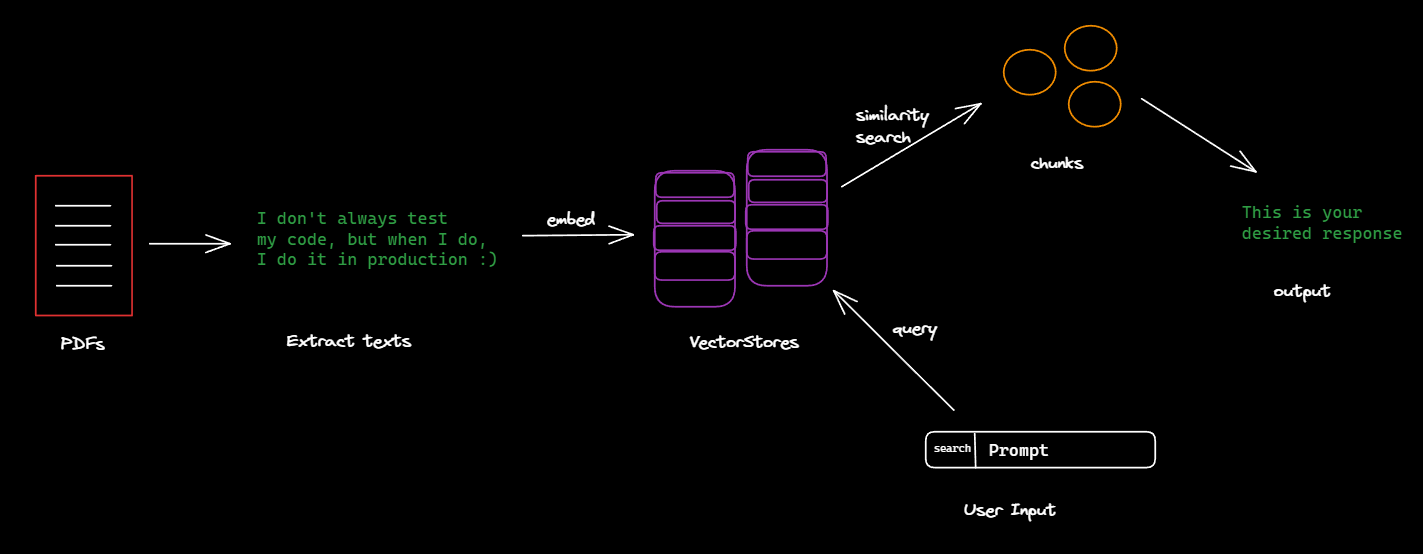
Working of LangChain: Behind the Scenes 😶🌫️
LangChain provides a variety of ways to load documents and process the text present inside those documents by breaking them down into small chunks or pieces. These chunks are then embedded into a VectorStore which is a data structure to store those chunks in an optimized way.
When we insert a prompt, LangChain will query that prompt in the VectorStore and will try to search for similar chunks in the VectorStore to give the relevant response.
These things are quite complicated to create completely from scratch by a developer, but LangChain abstracts all those processes, making it easy for the developers to focus on the application & not on the implementation.
To learn more, about these available abstractions and the general use cases, you can refer to the official LangChain Documentation, which is available both in Python and Javascript languages.
Building the Chat App 🚀
Now that we have understood internal working in an easy and high-level way, let's dive right into building the application.
Before building the app, we first need to ensure that we do have all the required dependencies, so let's install these dependencies first. To install them, you need to have pip installed on your system.
# install dependencies
pip install langchain
pip install streamlit
pip install PyPDF2
LangChain - This is the framework we have been talking about all along.
Streamlit - Popular Python library, which is used to build web apps. To know more about the components & all other things that Streamlit allows us to do, visit Streamlit Docs.
PyPDF2 - It is another library, which helps in reading the contents of a PDF file.
Coding 🧑🏽💻
Import Libraries
Let's first import all the required packages for our app. Create a Python application with the name "app.py". Inside the file, we will need the os package to use our OpenAI API key, streamlet, PdfReader from PyPDF2 and a few other classes from the LangChain package.
import os import streamlit as st from PyPDF2 import PdfReader from langchain.chat_models import ChatOpenAI from langchain.text_splitter import RecursiveCharacterTextSplitter from langchain.embeddings.openai import OpenAIEmbeddings from langchain.vectorstores import FAISS from langchain.callbacks import get_openai_callback from langchain.chains.question_answering import load_qa_chainOpenAI API key
Now, this is a deciding phase where you have to decide how your application is going to work. You can either provide your own OpenAI API key in the application or you can ask the user of the application to enter their API key while using the application. Let's understand, how to get your API key:
Go to openai.com and log in with your account.
After signing up, you'll get three options to choose from, choose the API section.
You'll be redirected to the OpenAI Platform.
Here in the top-right corner, tap on your profile and choose Manage Account.
In the API Keys section, you can create a new secret key, that'll be your API key.
💡Note that, if your free usage limit has expired, you will need to buy OpenAI credits.
Basic Setup of the application
When using Streamlit, we need to define a main() function, which will be the main entry point of our application. We write the title, using basic Streamlit syntax.
Now, we will add the OpenAI API key. You can either add your API key (line 2) or ask the user to input their own API key (line 3). Then, just use the os module to use the key.
def main(): st.title("Chat with your Documents 💬") # openaikey = "sk-gfuogbfbuob3o1buodouvbvobfeohfobfobb" openaikey = st.text_input("Your OpenAI API key: ", type="password") os.environ["OPENAI_API_KEY"] = openaikey if __name__ == '__main__': main()💡Here onwards, all the code we will write, we'll be writing them inside the main() function.Upload the PDF files
Now it's time to use the file_uploader widget provided by Streamlit to let users upload PDF files.
uploadedFiles = st.file_uploader("Upload your PDF files.", type=['pdf'], accept_multiple_files=True)After the files are uploaded, we will extract the text present inside the PDF files and convert them into a string.
text = "" for file in uploadedFiles: file_reader = PdfReader(file) for page in file_reader.pages: text += page.extract_text()Convert the extracted text into chunks
The next step is to, convert the extracted texts into small chunks. To do that, we will make use of the RecursiveCharacterTextSplitter.
The RecursiveCharacterTextSplitter class is the recommended way of splitting generic text into chunks. It keeps on splitting the text until it is small enough and then arranges those chunks in the form of a list to keep all the paragraphs as close as possible.
chunk_size: It defines the size of each chunk that the text will be split into.
chunk_overlap: It defines how much text will be overlapped so that the context of the content can stay put.
For example, we have a paragraph: "Lori lived her life through the lens of a camera. She never realized this until this very moment as she scrolled through thousands of images on your computer."
After breaking down into chunks, it may become something like this:
["Lori lived her life through the lens of a camera. She never realized", "this until this very moment as she scrolled through", "thousands of images on your computer."]
As we can see, some of the contexts can be lost due to the size of the chunks. To overcome this, we will overlap a certain part of the text, like this:
["Lori lived her life through the lens of a camera. She never realized this until this very moment", "this until this very moment as she scrolled through thousands of images on your computer", "thousands of images on your computer."]
length_function: This just defines the overall length of the text we want to convert into chunks.
if(len(text) != 0): text_splitter = RecursiveCharacterTextSplitter( chunk_size=500, chunk_overlap=20, length_function=len ) chunks = text_splitter.split_text(text=text) st.success("Successfully uploaded files")
Embed the chunks into a VectorStore
This is one of the most important, yet the most abstract part of the project. This shows the beauty of LangChain. We will use the available OpenAIEmbeddings class provided by LangChain to convert our texts into Vector Representations so that they can be stored in our VectorStore.
Now, what is vector representation & why we need them is a little advanced topic, which you can understand by a Google Search. For now, you can just understand that, we need to convert the text into vector representation as VectorStore can only store vectors, hence the name.
Here, we have used another class FAISS, which stands for Facebook AI Similarity Search. It enables efficient similarity search & clustering of dense vectors. In line 2, we are taking all the chunks, converting them into vectors & then clustering them. Clustering is another big topic, which you can understand through the internet, but in short, it groups similar things based on certain properties.
embeddings = OpenAIEmbeddings() VectorStore = FAISS.from_texts(chunks, embedding=embeddings)Taking user Queries
The next step is to take a prompt from the user, we will use the text_input widget of the Streamlit Library. After the user enters the prompt, we will use the "Similarity Search" functionality provided by FAISS, to do searching for similar content present in our VectorStore. The k value refers to the number of nearest neighbors to search to get additional context.
Chaining & generating Response
This is the last step of our application and also one of the most crucial steps. Here, first of all, we will define which LLM model we want to use, as we are creating a ChatBot application, we are using the ChatOpenAI function, and here we define the LLM model in the model_name attribute. We also define the temperature of the model, which is the randomness in the response provided by the LLM.
Next, LangChain provides a powerful feature, which is to create Chains. Chains enable users to combine multiple components to create a single application. In simple words, Chains in the context of Langchain refer to a feature that allows for the creation of a sequence of language model calls. It enables the output of one call to be used as the input for another call. This is useful for scenarios where multiple steps are required to achieve a specific task. To read more about Chains and their types, refer here.
In our application, we are using the default chain type i.e., stuff and loading the chain using the load_qa_chain function, which is a question-answering chain.
At last, we will provide the input_documents, which will take the documents we have fetched after doing a similarity search and the prompt entered by the user to the chain and then run it to generate the desired result.
query = st.text_input("Ask questions about your file:") if query: k = 10 # Number of nearest neighbors to retrieve distances = [] # List to store the distances labels = [] docs = VectorStore.similarity_search( query=query, k=k, distances=distances, labels=labels) llm = ChatOpenAI(temperature=0.07, model_name="gpt-3.5-turbo") chain = load_qa_chain(llm=llm, chain_type="stuff") response = chain.run(input_documents=docs, question=query) st.divider() st.subheader("Answer: ") st.write(response) st.divider()Running the Application
Just when we thought everything is done, we forgot an important task i.e., running the application :)
To run a Streamlit application, open your command line in your editor, and run the following command:
streamlit run app.pyThe application will open in your localhost:8501 and will look something like this:
And done!!
Now you can test your application, by putting an OpenAI key, uploading multiple PDF files, entering a prompt and just waiting for the answer.
Conclusion
This was just a small demonstration of what AI & LangChain is capable of. I know, the LangChain documentation is not that great as of now, as they launched recently. With time, we will have ample resources and better documentation to create many complex projects with them. For now, you can try to add the functionality to add multiple file formats or you can customize this application to read the contents of a website and ask questions based on them. You can also deploy this application using Streamlit Cloud. The possibilities are endless. I hope, you enjoyed this article and I expect that this article helped you to create an awesome project for yourself. Thanks for reading this to the end.
You can find a similar application that I created live here 👇
https://docbot-chat.streamlit.app/
Code - https://github.com/SujalSamai/customBot
Hi there! I’m always on the lookout for internships, freelancing opportunities and writing/coding gigs to keep broadening my online content. Any support, feedback and suggestions are very much appreciated! Interested? Drop an email here: sujalsamai.work@gmail.com
